
Wenn Computer träumen - ein Exkurs in die Welt der AI Text-to-Image Generierung mit Midjourney
Ein Blick über den Tellerrand und hinein in die Welt des Creative Computing. Sind wir demnächst alle Künstler?
Background
Das Thema Bildgenerierung und -manipulierung durch Computer wird immer präsenter. Seit man 2015 von Googles DeepDream hörte und die ersten psychedelischen Bilder aus neuronalen Netzwerken sah, ist nur verhältnismäßig wenig Zeit vergangen. Was sich in diesem Zeitraum getan hat, ist jedoch fast schon unglaublich.
Da mittlerweile ganz neue Services und Modelle entwickelt wurden - vor allem die Innovation in der Text-to-Image Generierung und dem Upscaling sei hier genannt - ist die Technologie nun wesentlich zugänglicher, kontrollierbarer und daher einsteigerfreundlicher geworden.
Als Teil unserer wöchentlichen TeamTime (freie Weiterbildungszeit, in der nicht an Kundenprojekten gearbeitet wird) haben ein paar Kollegen und ich mit einigen dieser Services gespielt, um ein Gefühl für das Potenzial der Technologie im aktuellen Zustand zu erhalten.
Historie
Frühe Text-to-Image Modelle basierten vor allem auf dem Remix von mehreren bestehenden Cliparts zu Kollagen. Wie man sich vorstellen kann, war dieser Ansatz recht beschränkt und ließ wenig künstlerische Freiheit zu. Außerdem konnte man nur Begriffe verwenden, zu denen das Modell auch eine Clipart kannte. Es konnte sich sozusagen keine neuen Dinge "ausdenken".

Als erstes "modernes" Text-to-Image Model wurde alignDraw 2015 von der University of Toronto veröffentlicht. Dieses konnte bereits mit Texteingaben konditioniert werden und eigene Varianten erschaffen, die nicht im Trainings-Datenset vorhanden waren. Die Bilder waren noch recht klein, verwaschen und unscharf, aber der Grundgedanke funktionierte: dem Computer in Textform zu sagen, was man haben möchte und daraus Bilder generieren. Außerdem konnte alignDraw sich neue Dinge "ausdenken" - z.B. einen roten Schulbus, obwohl das Modell nur mit gelben Schulbussen trainiert wurde.
Über die anschließenden Jahre wurden immer genauere, spezialisierte Modelle trainiert, die immer näher an "visuelle Plausibilität" heranreichten. Zudem entwickelten die ersten Modelle eine Art "Kreativität", bei der sie fehlende Information in den Texteingaben durch randomisierte Zuordnungen ergänzten.
Mit OpenAI's proprietärem DALL-E rückte 2021 das Thema wieder ins Bewusstsein der breiten Öffentlichkeit. Es arbeitet mit der sogenannten Transformer-Methode, um seine Bilder zu generieren. 2022 wurde Version 2 veröffentlicht, welche noch realistischere und komplexere Bilder erzeugen kann.

Mit Stable Diffusion erblickte zudem das erste große Open Source Projekt in diesem Bereich das Licht. Stable Diffusion zeichnet sich durch einige Features aus, die sich von den übrigen proprietären Anbietern absetzen. So ermöglicht es Stable Diffusion, "vorhersehbarere" Ergebnisse zu erzielen, indem man sehr genaue Inputs - u.a. in Form von Tiefenmasken - liefert. Und da der Quellcode öffentlich verfügbar ist, kann man auf eine rapide Weiterentwicklung und interessante Forks hoffen.
Im Juli 2022 wurde zudem die Beta von Midjourney veröffentlicht. Midjourney ist ein unabhängiges Forschungslabor, welches ebenfalls eine proprietäre Text-to-Image Lösung entwickelt hat. Die Besonderheit: Jeder kann teilnehmen und das Tool ausprobieren, ohne selbst Software hosten zu müssen oder überhaupt etwas zu bezahlen (25 Bilder sind testweise kostenlos).
Experimente
Um erste Experimente mit Text-to-Image Generierung zu machen, haben wir uns für Midjourney entschieden - aus mehreren Gründen:
- Kein eigenes Hosting nötig
- Kostenlos (25 initiale Bilder) / Kostengünstig (für 30$/Monat kann man beliebig viele Bilder generieren)
- Qualität der generierten Bilder (Midjourney soll eine "ernstere" Ästhetik als viele Konkurrenten aufweisen)
- Der Hype (Wann immer es um dieses Thema geht, wird Midjourney als ein hervorragendes Beispiel genannt, es scheint das beliebteste Tool zu sein)
First steps
So begann also unsere Reise in die Welt der Text-to-Image Bildgenerierung. Midjourneys User Interface ist momentan noch ein einfacher Discord-Bot, also benutzten wir Discord als App, um die Bilder zu generieren. Um ein Prompt (als "Prompt" werden die Text-Anfragen bezeichnet) an den Service zu senden, schickt man einfach eine Nachricht an den Midjourney Bot, die mit "/imagine" (zu Deutsch "stell dir vor") anfängt.
Als anschauliches Beispiel benutzen wir im Folgenden den Prompt "earth, fish", also unseren Firmennamen dekonstruiert in seine Einzelteile. Und siehe da, wir bekommen einige ganz passable Motive:
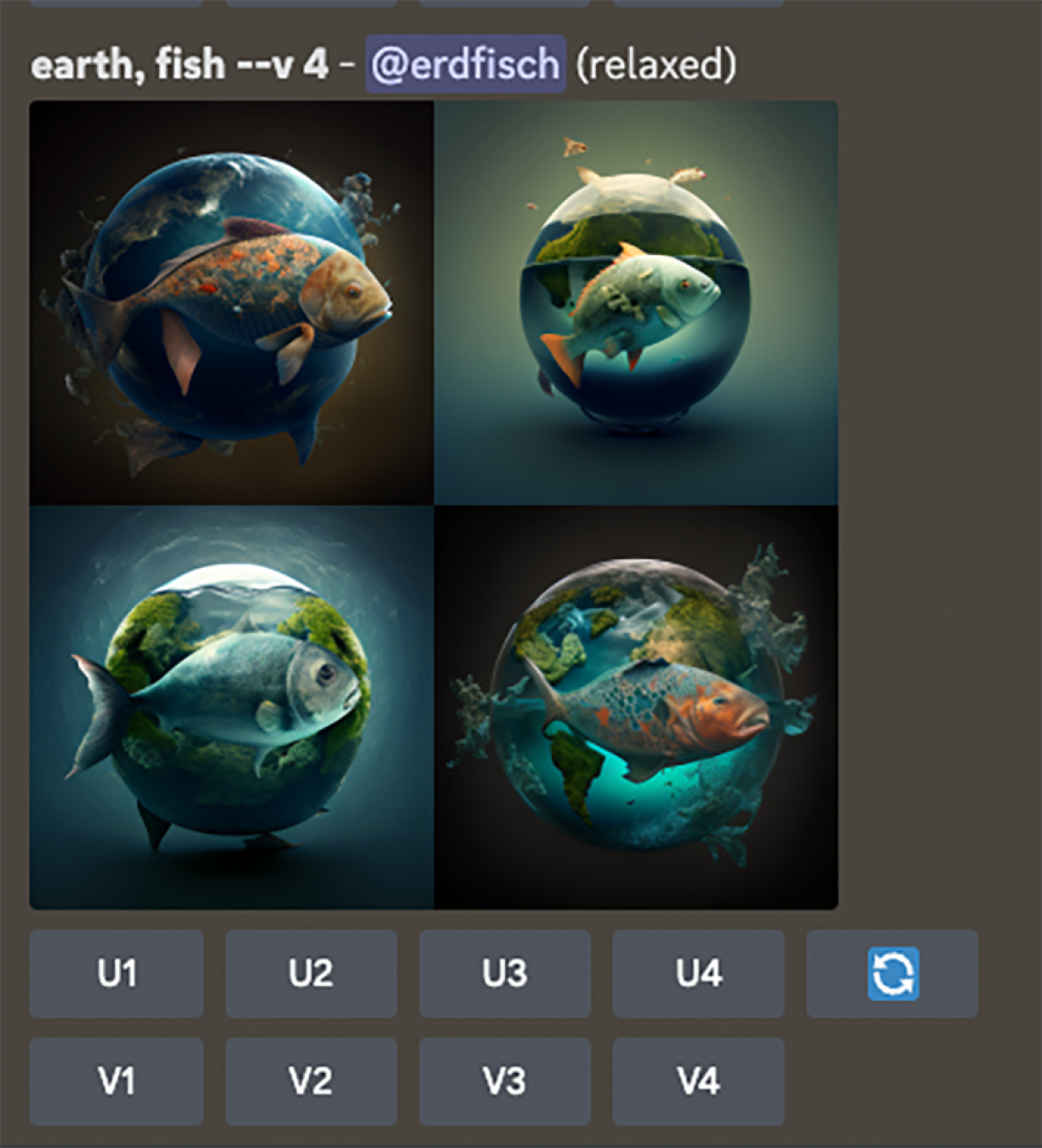
Es fällt auf, dass Midjourney immer vier Varianten zu einer Eingabe generiert. Da beim Generieren der Bilder immer ein bisschen der Zufall (oder die ungerichtete Kreativität der Maschine?) mitspielt, ist dies eine gute Methode, um einen ersten Überblick zu erhalten, was für Ergebnisse man mit dem Prompt erzielen kann. Unter jedem initialen Prompt bekommt man neun Buttons, mit denen man das Ergebnis weiter ausarbeiten kann. Die Buchstaben stehen dabei für die Methode, die angewendet werden soll, die Zahl für das Bild in den Kacheln.
- "U" steht für "Upscale" - also die Vergrößerung des Bildes. Damit ist nicht nur ein reines vergrößern, was die Auflösung angeht gemeint - sondern auch ein "auffüllen" der entstehenden Leerräume mit Details. Das Bild wird beim Upscale also sowohl von der Auflösung als auch von den Details her raffinierter.
- "V" steht für "Variants" - also die Erstellung von Varianten aus dieser Version des Bildes. Dies kann hilfreich sein, wenn das generierte Bild schon nah an der gewünschten Komposition ist, jedoch irgendwas nicht stimmt oder man sich unsicher ist, ob es nicht noch bei einem neuen Versuch besser wird. Die Varianten werden aus dem Ursprungsbild generiert und sind diesem deshalb visuell immer sehr nah.
- Der "Refresh-Button" (blaues Icon) sendet das Prompt noch einmal ab, sodass mit einem neuen Seed ein weiterer Versuch gestartet wird. Er sorgt quasi dafür, dass die Bilder "neu gewürfelt" werden. Wenn man sich sicher ist, dass das Prompt genau genug ist, aber die Ergebnisse einem nicht gefallen, kann es Sinn machen ein paar mal zu "würfeln" bis ein Bild mit der gewünschten Komposition / Ästhetik entsteht.

Verschiedene Stile erzeugen
Mit dieser einfachen Methode des Anfragens und danach immer weiter Selektierens kann man bereits zu sehr ansprechenden Ergebnissen gelangen. So richtig interessant wird es jedoch, wenn man nicht nur spezifiziert, was man sehen möchte, sondern auch in welchem Stil das Bild sein soll. Generell kann man Assoziationen zu Stilen, Kunstformen oder sogar die Namen bekannter Künstler hinzufügen, um gewisse Stile zu erzwingen. Es gibt mittlerweile ganze Plattformen im Internet, welche nur Prompt-Textblöcke sammeln, die interessante Stile generieren. Einige haben sogar bereits angefangen, Prompts, die zuverlässig einen gewissen Stil zu generieren, zu verkaufen.
Im Folgenden einige einfache Beispiele von Ergänzungen zum Prompt "earth, fish", die ganz unterschiedliche Artstyles generieren.

Bilder detailliert beschreiben
Bei so offenen Anfragen wie "earth, fish" ist es vor allem interessant zu sehen, was die Maschine am Ende daraus macht. Wenn die "freie" Interpretation einem jedoch nicht gefällt, wird es Zeit spezifischer zu werden. So kann man den Prompt immer mehr erweitern und Stück für Stück testen, ob man sich mit den Änderungen dem gewünschten Ziel annähert. Dies kann auf unterschiedliche Weisen geschehen, hier ein paar Tipps:
- Dinge mit "--no" ausschließen: Wenn man im Prompt "--no" eingibt, werden alle Begriffe, die danach kommen, auf eine "Negativliste" gesetzt. Es wird bei der Generierung versucht, diese Elemente möglichst nicht erscheinen zu lassen. So haben wir z.B. bei einigen der oben dargestellten Bildern gesehen, dass die Erdkugel Flossen bekommen hat. Mit "--no fins" könnte man dies z.B. unterdrücken.
- Die Szenerie genauer beschreiben: man kann dem Modell recht detailliert erläutern, was genau man sehen möchte. So kann man z.B. einen Raum im Detail beschreiben: welche Bilder hängen an der Wand? Was steht auf dem Tisch? Hat der Raum Fenster? Welche Möbel / Wesen befinden sich in ihm? Je genauer die Beschreibung, desto homogener werden die Ergebnisse.
- Sich von der Community inspirieren lassen: Da (wenn man nicht zusätzlich dafür bezahlt hat) alle generierten Bilder öffentlich sind, kann man sich sehr gut auch von erfolgreichen Community-Mitgliedern inspirieren lassen. Unter midjourney.com findet man viele unglaublich gut gelungene Ergebnisse, bei denen man als angemeldeter User auch das benutzte Prompt auslesen kann. So kann man von anderen Community-Mitgliedern lernen, welche Begriffe und Assoziationen zu welchen Ergebnissen führen und diese selbst ausprobieren. Hier findet man übrigens unseren Testaccount mit all seinen Testbildern.

Upscaling
Sobald man ein Motiv mit interessanter Komposition / Stimmung erstellt hat, kann man dieses mit verschiedenen Methoden "Upscalen". Upscaling im Kontext von Text-to-Image Modellen bedeutet nicht nur ein Vergrößern der Auflösung, sondern auch ein "anreichern" mit Details. Da in der Methode von kleinen groben Grafiken zu großen detaillierten Grafiken skaliert wird, muss die Maschine die entstehenden "Lücken" auffüllen. Hierfür kommen verschiedene Algorithmen zum Einsatz. Aktuell gibt es bei Midjourney den "Detailed Upscale", "Light Upscale" und "Beta Upscale".
Der "Detailed Upscale" ist die Standard-Methode und wird für den Initialen Upscale verwendet.
Der "Light Upscale" fügt nicht so viele kleinteilige Details hinzu und Ästhetik ist etwas "weicher". Somit kommt die "Light"-Variante besser an das ursprüngliche Bild ran und ist besser geeignet für abstrakte Elemente, Gesichter oder glatte Oberflächen.
Der "Beta Upscale" produziert etwas höhere Auflösungen, addiert aber auch mehr Details zum Bild. So kann es sein, dass dieses von der Ästhetik stärker vom Ursprung abweicht, oder manchmal auch zu viel "Struktur" (Noise) erhält.
Welcher Algorithmus ästhetisch besser funktioniert, musste in der Praxis bei vielen Motiven einfach ausprobiert werden. Generell kann man aber sagen, dass realistische, detaillierte Motive besser mit dem Beta-Upscaler funktionieren, als einfache, flache Motive.

Bilder als Input
Zusätzlich zur reinen Text-to-Image Generierung kann man auch bereits vorhandene Bilder als Ausgangspunkt angeben. So kann man zusätzlich zum Text-Prompt die URLs zu Bildern im öffentlichen Internet angeben, und Midjourney behandelt diese dann als einen weiteren Input. So lassen sich z.B. Porträts von Personen nutzen. Midjourney erstellt daraus dann Porträts in neuen Stilen, je nach Input.
Ebenso kann man Bilder von Szenerien eingeben und diese mit einer neuen Stimmung versehen. Außerdem ist es möglich, mehrere Bilder miteinander zu kombinieren. So könnte man z.B. ein zuvor erstelltes Bild als Hintergrund nehmen und dort die Person eines anderen Bildes hineinkopieren.

Die Experience
Was beim Ausprobieren des Tools direkt auffiel: Es macht unglaublich viel Spaß, spontan entstandene Ideen einfach einzugeben und zu sehen, was dabei herauskommt. Teile des Teams haben noch tage- und nächtelang weiter Prompts abgesendet und Bilder generiert. Teilweise einfach aus Neugier. Teilweise um Bildmaterial für private Projekte in ungeahnter Geschwindigkeit und Qualität zu generieren. Für rapides Prototyping von visuellen Ideen ist es ein unglaublich effizientes Werkzeug.
Anwendungsgebiete
Die generierten Bilder sind meistens nicht perfekt - sie weisen oft Artefakte auf, wie dass z.B. eine Person nur vier oder sechs Finger hat oder Dinge, die zusammen hängen sollten, getrennt sind (die Maschine versteht nicht so richtig die Konzepte dessen, was sie da malt, sie erkennt nur Muster und reproduziert diese). Jedoch sind sie dabei so gut, dass die Ergebnisse auf den ersten Blick überzeugen - und in unserer schnelllebigen Medienwelt reicht dies meist aus. Je nach Motiv fallen die Artefakte und Fehler auch gar nicht auf, da sie als Teil des Stils erkannt werden.
Daraus ergeben sich ein paar interessante potenzielle Anwendungsgebiete, von denen ich zwei hier kurz vorstellen möchte.
In der Kreativwirtschaft
Vor allem im Marketing und Grafikdesign könnten Text-to-Image Modelle für eine Revolution sorgen.
Zum einen machen sie die unterschiedlichsten, handwerklich schwierigen visuellen Stile der breiten Masse zugänglich. Es ist nicht mehr nötig, jahrelange Übung im manuellen Zeichnen oder Retuschieren zu sammeln, um ansprechende Ergebnisse in einem gewissen Stil zu erschaffen. Innerhalb von wenigen Minuten kann man ein ähnliches Motiv als Ölgemälde, 3D-Render oder Bleistiftzeichnung generieren, ohne jemals einen Pinsel oder Stift in der Hand gehabt zu haben.
Zum anderen sind sie ein unglaublich hilfreiches Tool, um neue Ideen visuell zu skizzieren, bevor man viel Geld in ihre Realisierung investiert. Und durch das vor und zurück zwischen Mensch und Maschine ergibt sich ein einzigartiger, effizienter Kreativitätsprozess, den man am besten damit beschreiben könnte, dass Mensch und Maschine sich gegenseitig inspirieren.
Zumindest für digitale Produktionen (aufgrund der aktuell noch recht limitierten Auflösung) ergibt sich noch ein weiter Vorteil: Es ist viel zielgerichteter und billiger, passende Motive z.B. für Onlinemarketing oder Blogartikel generieren zu lassen, als Bildlizenzen zu kaufen. Sobald die Modelle effizient genug werden, um höhere Auflösungen zu generieren, könnte die Methode sich auch für Printproduktionen oder Außenwerbung eignen.
Ich denke allerdings nicht, dass dadurch plötzlich alle Grafiker arbeitslos werden. Zu visueller Kommunikation gehört mehr, als nur ansprechende Motive zu gestalten. Ich hoffe eher, dass viele Schaffende diese Technologie in ihren Prozess integrieren, um Ideen schnell zu skizzieren oder auszuprobieren, bevor sie Arbeit in klassische, handwerkliche Ausgestaltung ihrer Werke legen. Auch als Inspirationswerkzeug taugt diese Technologie ungemein und könnte von vielen Menschen in der Kreativwirtschaft dafür übernommen werden.
Automatisierte Artikelbilder für Redaktionen
Vorstellbar wäre auch eine Bridge zum Backend eines Drupal-Redaktionssystems zu implementieren. Das System könnte die wichtigsten Begriffe / Tags eines neuen Artikels automatisch an ein Text-to-Image Modell senden, um im Hintergrund während des Schreibens schon einmal ansprechende Artikelbilder zu generieren.
So könnte ein Redakteur z.B. nach Schreiben des Artikels durch ein einfaches Frage-Antwort-Spiel im Drupal-Backend automatisiert ein thematisch passendes Motiv generieren. Die Redaktion wäre nicht wie bisher auf Bilddatenbanken angewiesen, um Symbolbilder zu finden, sondern würde für jeden Artikel ein individuelles, einzigartiges Motiv generieren.
Indem man den Prompt, der im Hintergrund an das Modell gesendet wird, mit diversen Parametern "vorbefüllt", könnte man zudem dafür sorgen, dass ein einheitlicher Stil über die gesamte Redaktionsplattform hinweg genutzt wird, ohne dass die Redakteure darauf achten müssen. Dadurch kann man die visuelle Identität einer Plattform extrem effizient unterstützen. So könnte man z.B. festlegen, dass nur flache, illustrative 2D-Motive mit maximal fünf Farben verwendet werden. Am Ende verbinden die User diesen festgelegten Art style mit den Artikeln dieser Plattform und haben dadurch eine starke visuelle Bindung an die Marke.
Fazit
Die Ergebnisse sind wirklich sehr oft ästhetisch ansprechend. Und sie beinhalten oft Aspekte und Stile, die man im Prompt so gar nicht gefordert hat, aber durch die Maschine "hinzugedichtet" wurden.
Es ergibt sich ein Dialog zwischen Mensch und Maschine: Der Mensch gibt den initialen Prompt, die "Idee". Die Maschine macht daraus ihre Version. Der Mensch selektiert, was ihm gefällt, raffiniert den Prompt oder nimmt Dinge, die die Maschine hinzugedichtet hat und ihm gefallen, mit in den nächsten Prompt auf und startet von vorn.
So inspirieren sich Mensch und Maschine im Prozess gegenseitig und kommen auf Motive, die man sonst nie erdacht hätte. Ich bin wirklich gespannt, wohin uns diese Entwicklungen noch führen werden, aktuell scheinen wir erst an der Oberfläche des Potenzials dieser Technologie zu kratzen.
Eines ist sicher: Text-to-Image Modelle werden Einzug in meinen Werkzeugkasten halten, und Midjourney war nur der Anfang.


